WWII Morning Reports in PDF Files

My newest presentation is about finding the genealogical gold buried in WWI and WWII Morning Reports. I have been spending time working on a companion book so that readers could a resource with them as they search for and use Morning Reports. This has been leading me to experiment with the finer points of searching for WWII Morning Reports through the NARA Catalog.
The caveats are:
1) Search from the NARA Catalog (https://catalog.archives.gov). You don’t always get links to show where the search results occur in the images within the File Unit, but searching from the Catalog (rather than within the Series) is the only way to see links at all.
2) Don’t use Firefox. Use a web browser other than Firefox for searching Morning Reports. There is a known bug where Firefox display images in reverse order, and that can make things more complicated than they need to be. (I use Chrome.)
Although I have not had confirmation from NARA that PDF files are available for every Month/Year and Roll Number combination in the Morning Report series in Record Group 64, a pattern has emerged. Rather than having to download every image separately, there appears to be a way to download the images from a Roll in the form of PDF files that contain groups of 125 images. Considering the convenience of having these Morning Reports online, the time to download each image was not objectionable. Individual images can be downloaded in .tif file format, so you may choose to that option.
For context, the Morning Reports were photographed onto Rolls (Reels) of film. These Rolls were digitized. NARA split the Rolls into File Units, which are parts of the Roll having 1000 images, with fewer images in the last part of the Roll (the end of the Roll). Those parts are File Units, and are labeled with the Roll Number and have numbers like these at the end (1 of 4), (2 of 4), (4 of 5). The number after “of” is the number of parts that the Roll was divided into.
The math that follows is just one way to calculate which PDF file to download, and how to figure the page within the PDF file. This is intended to be a primitive introduction, to go through the process step-by-step.
Example: I located a Special Order containing the search term in the Morning Reports. It was in the File Unit:
Morning Reports for January 1940 – July 1943: Roll 718 (3 of 4)
at: https://catalog.archives.gov/id/426912282?objectPage=431
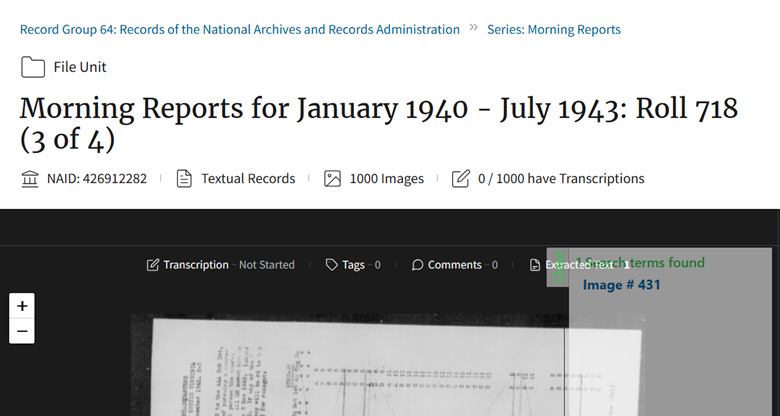
I made a note of the image number, and which part of the Roll it was on (3 of 4).
I knew that:
Roll 718 (1 of 4) had images 1-1000 of the whole Roll
Roll 718 (2 of 4) had images 1001-2000 of the whole Roll
Roll 718 (3 of 4) was the image of interest to me, image number 431
I am looking for what would be image 2431 on the whole Roll.
Knowing that each PDF file has 125 pages, I divided 2431/125 = 19.45
The image would be in the PDF file ending in -20
Doing a little more math, the number of images in the previous 19 PDF files would be
19 x 125 = 2375 images
subtracting all those images from the calculated image number
2431 – 2375 = 56
I would expect to see the page I was looking at in the PDF file ending in -20, on page 56 of that PDF file
So, I searched from the Catalog for:
“Morning Reports for January 1940 – July 1943″ AND “Roll 718 (4 of 4)”
The one search results was for: https://catalog.archives.gov/id/426913283
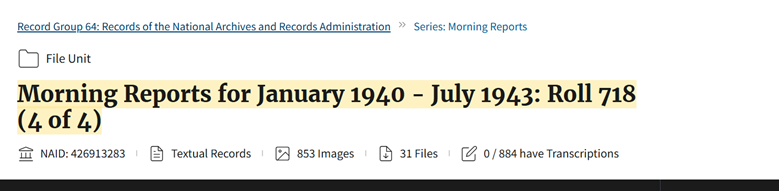
As expected, the PDF files were posted on the webpage with the end of this Roll. I downloaded the PDF file ending in -20, on page 56.
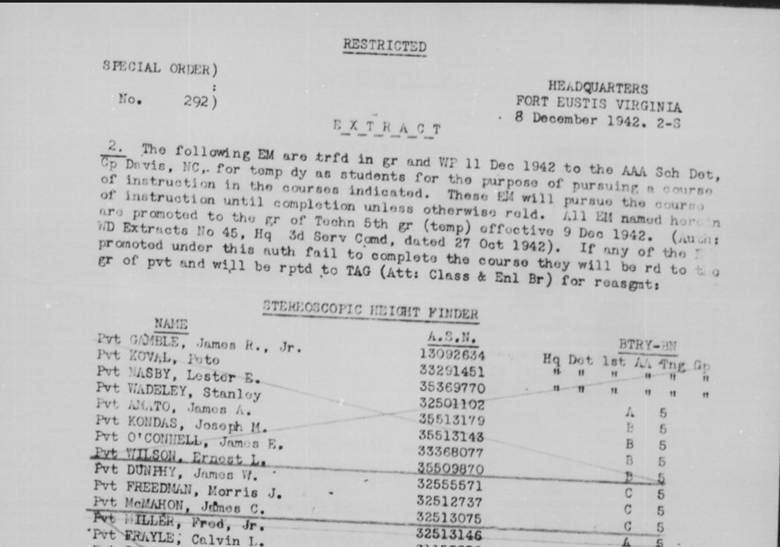
At the Coast Artillery Replacement Center in Fort Eustis, Virginia, troops were trained in anti-aircraft artillery. This Special Order was how my father came to be trained at a school for using the Stereoscopic Height Finder at Camp Davis, North Carolina.
Remember that for the best chance to have links to where search terms appear within the parts of a Roll (File Units), is to search from https://catalog.archives.gov, and remember to view the search results within the same tab.
Good luck, and let me know how you do!


